como fazer teste de hipótese para comparar valores exatos com valores >5
2 participantes
Página 1 de 1

como fazer teste de hipótese para comparar valores exatos com valores >5
por robertamfs Sex Nov 09, 2018 1:35 am
Boa noite,
Tenho valores de amostras de amônia de 0 a 4,7 nos tratamentos experimentais com plantas. Mas tive alguns resultados que o valor foi acima de 5 para os tratamentos controle e não obtive o valor exato porque passou da escala de capacidade de análise que era até 5. Tem alguma forma de fazer teste de hipótese para comparar se tem diferença significativa dessa variável para dois tipos de tratamento com 4 réplicas independentes cada um?
Foi sugerido no webnário trabalhar com valores ordinais. Rankiar e agrupar até 5 ou mais.
Pode me auxiliar como fazer, por favor?
Tenho esses valores:
semana 1
- amostras tratamento controle: 0.02, 0.02, 0.02, 0.02
- amostras tratamento experimento: 0.02, 0.02, 0.02, 0.02
semana 2
- amostras tratamento controle: 0.12, 0.22, 0.42, 0.13
- amostras tratamento experimento: 0.15, 0.04, 0.03, 0.12
semana 3
- amostras tratamento controle: 0.32, 0.42, 0.22, 0.63
- amostras tratamento experimento: 0.22, 0.14, 0.13, 0.14
semana 4
- amostras tratamento controle: 1.32, 2.42, 3.22, 2.63
- amostras tratamento experimento: 0.52, 0.38, 0.72, 0.84
semana 5
- amostras tratamento controle: 3.32, 4.42, 3.22, 3.63
- amostras tratamento experimento: 0.82, 0.98, 1.72, 1.84
semana 6
- amostras tratamento controle: 4.32, >5, 4.22, 3.80
- amostras tratamento experimento: 1.82, 0.98, 2.72, 2.84
semana 7
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 1.05, 1.07, 1.5, 2.8
semana 8
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 1.7, 1.52, 1.5, 1.8
semana 9
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 2.7, 1.52, 2.5, 4.8
Tenho valores de amostras de amônia de 0 a 4,7 nos tratamentos experimentais com plantas. Mas tive alguns resultados que o valor foi acima de 5 para os tratamentos controle e não obtive o valor exato porque passou da escala de capacidade de análise que era até 5. Tem alguma forma de fazer teste de hipótese para comparar se tem diferença significativa dessa variável para dois tipos de tratamento com 4 réplicas independentes cada um?
Foi sugerido no webnário trabalhar com valores ordinais. Rankiar e agrupar até 5 ou mais.
Pode me auxiliar como fazer, por favor?
Tenho esses valores:
semana 1
- amostras tratamento controle: 0.02, 0.02, 0.02, 0.02
- amostras tratamento experimento: 0.02, 0.02, 0.02, 0.02
semana 2
- amostras tratamento controle: 0.12, 0.22, 0.42, 0.13
- amostras tratamento experimento: 0.15, 0.04, 0.03, 0.12
semana 3
- amostras tratamento controle: 0.32, 0.42, 0.22, 0.63
- amostras tratamento experimento: 0.22, 0.14, 0.13, 0.14
semana 4
- amostras tratamento controle: 1.32, 2.42, 3.22, 2.63
- amostras tratamento experimento: 0.52, 0.38, 0.72, 0.84
semana 5
- amostras tratamento controle: 3.32, 4.42, 3.22, 3.63
- amostras tratamento experimento: 0.82, 0.98, 1.72, 1.84
semana 6
- amostras tratamento controle: 4.32, >5, 4.22, 3.80
- amostras tratamento experimento: 1.82, 0.98, 2.72, 2.84
semana 7
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 1.05, 1.07, 1.5, 2.8
semana 8
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 1.7, 1.52, 1.5, 1.8
semana 9
- amostras tratamento controle: >5, >5, >5, >5
- amostras tratamento experimento: 2.7, 1.52, 2.5, 4.8
robertamfs- Mensagens : 32
Data de inscrição : 17/09/2018
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por Prof. Marcos Sex Nov 09, 2018 5:46 pm
Olá, Roberta, tudo bem?
Hoje passei um tempinho pesquisando sobre dados que tem limite máximo de medição. Os termos são meio chatos de traduzir, em inglês falamos em "censored data", que em uma tradução seriam dados censurados, o que soa bem estranho.
No seu caso, temos dados que são "right censored": ou seja, eles tem um limite máximo de medição. Isto é diferente do termo que eu usei no webnário, que são dados truncados, que é o caso para valores acima ou abaixo de um certo limite serem excluídos de uma análise. Qualquer coisa leia aqui para as definições: https://www.theanalysisfactor.com/the-difference-between-truncated-and-censored-data/
Bom, dados right censored são comuns em uma família de análises chamada de análise de sobrevivência, mas eu acho que não seria simples de adaptar análises deste tipo para os seus dados, de forma que podemos buscar outra alternativa.
Eu penso em duas possibilidades:
1 - Se você tiver evidências de que os valores acima de 5 vão pouco acima deste valor, uma possibilidade é considerá-los como 5 mesmo e seguir adiante. Mas isso se você tiver segurança e puder argumentar para mostrar que isso deve ser verdade. Neste caso, você seguiria com uma análise normal mesmo, e pronto.
2 - Caso você não consiga seguir pelo primeiro caminho, então volto ao que sugeri no webnário, que seria trabalhar de maneira ordinal. Uma saída rápida seria trabalhar diretamente com um teste não paramétrico que ranqueia os dados. Nesta abordagem, eu diria que você poderia substituir os valores 5> por 6, e seguir com o teste. Como o teste vai ranquear os dados, então todos os valores serão ordenados, e os valores acima de 5 serão todos colocados no topo do rank.
Acho que é isso. Qualquer coisa seguimos conversando mais sobre isso, ok?
Abraços
Hoje passei um tempinho pesquisando sobre dados que tem limite máximo de medição. Os termos são meio chatos de traduzir, em inglês falamos em "censored data", que em uma tradução seriam dados censurados, o que soa bem estranho.
No seu caso, temos dados que são "right censored": ou seja, eles tem um limite máximo de medição. Isto é diferente do termo que eu usei no webnário, que são dados truncados, que é o caso para valores acima ou abaixo de um certo limite serem excluídos de uma análise. Qualquer coisa leia aqui para as definições: https://www.theanalysisfactor.com/the-difference-between-truncated-and-censored-data/
Bom, dados right censored são comuns em uma família de análises chamada de análise de sobrevivência, mas eu acho que não seria simples de adaptar análises deste tipo para os seus dados, de forma que podemos buscar outra alternativa.
Eu penso em duas possibilidades:
1 - Se você tiver evidências de que os valores acima de 5 vão pouco acima deste valor, uma possibilidade é considerá-los como 5 mesmo e seguir adiante. Mas isso se você tiver segurança e puder argumentar para mostrar que isso deve ser verdade. Neste caso, você seguiria com uma análise normal mesmo, e pronto.
2 - Caso você não consiga seguir pelo primeiro caminho, então volto ao que sugeri no webnário, que seria trabalhar de maneira ordinal. Uma saída rápida seria trabalhar diretamente com um teste não paramétrico que ranqueia os dados. Nesta abordagem, eu diria que você poderia substituir os valores 5> por 6, e seguir com o teste. Como o teste vai ranquear os dados, então todos os valores serão ordenados, e os valores acima de 5 serão todos colocados no topo do rank.
Acho que é isso. Qualquer coisa seguimos conversando mais sobre isso, ok?
Abraços

Prof. Marcos- Mensagens : 678
Data de inscrição : 23/12/2015
Idade : 42
Localização : Maceió, AL -

Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por robertamfs Sex Nov 09, 2018 10:52 pm
Prof. Marcos, boa noite.
Grata pelas instruções. O sr. pode indicar qual é o teste não paramétrico mais indicado para o caso 2? Pois na verdade possivelmente por algumas pistas os valores são bem maiores que 5.
Grata pelas instruções. O sr. pode indicar qual é o teste não paramétrico mais indicado para o caso 2? Pois na verdade possivelmente por algumas pistas os valores são bem maiores que 5.
robertamfs- Mensagens : 32
Data de inscrição : 17/09/2018
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por robertamfs Sáb Nov 10, 2018 1:50 am
Boa noite prof. Marcos,
Grata pela resposta. Encontrei nas aulas 5.3 (aprendendo sobre transformação e rankeamento de dados), 5.4 (teste não paramétrico de Mann-Whitney) e 5.9 (teste não paramétrico - ANOVA simples) como fazer para uma amostra simples e usei para a semana 9 o teste de Mann-Whitney, como segue no final.
Mas ficaram ainda algumas dúvidas:
- Como devo descrever no artigo essa forma de tratamento dos dados, com respaldo na literatura?;
- Tem como fazer considerando todas as semanas para comparar diferenças significativas entre tratamentos, entre semanas e tratamentos x semanas?
Exemplo:
semana 9
- amostras tratamento controle: >5, >5, >5, >5 - dados mudados para 6.0, 6.0, 6.0, 6.0
- amostras tratamento experimento: 2.7, 1.52, 2.5, 4.8
#script:
> dados<-read.table("clipboard", h=T)
> dados
trat rep A
1 C 1 6.00
2 C 2 6.00
3 C 3 6.00
4 C 4 6.00
5 E 1 2.70
6 E 2 1.52
7 E 3 2.50
8 E 4 4.80
> qqnorm(dados$A)
> qqline(dados$A, lty=2)
> wilcox.test(dados$A~dados$trat)
Wilcoxon rank sum test with continuity correction
data: dados$A by dados$trat
W = 16, p-value = 0.02107
alternative hypothesis: true location shift is not equal to 0
Warning message:
In wilcox.test.default(x = c(6, 6, 6, 6), y = c(2.7, 1.52, 2.5, :
cannot compute exact p-value with ties
> boxplot (dados$A~dados$trat, las=1)
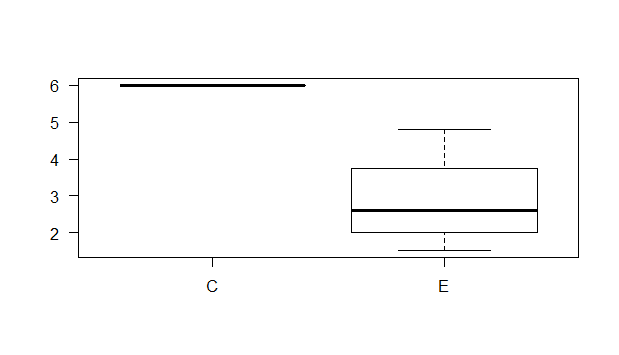
Grata pela resposta. Encontrei nas aulas 5.3 (aprendendo sobre transformação e rankeamento de dados), 5.4 (teste não paramétrico de Mann-Whitney) e 5.9 (teste não paramétrico - ANOVA simples) como fazer para uma amostra simples e usei para a semana 9 o teste de Mann-Whitney, como segue no final.
Mas ficaram ainda algumas dúvidas:
- Como devo descrever no artigo essa forma de tratamento dos dados, com respaldo na literatura?;
- Tem como fazer considerando todas as semanas para comparar diferenças significativas entre tratamentos, entre semanas e tratamentos x semanas?
Exemplo:
semana 9
- amostras tratamento controle: >5, >5, >5, >5 - dados mudados para 6.0, 6.0, 6.0, 6.0
- amostras tratamento experimento: 2.7, 1.52, 2.5, 4.8
#script:
> dados<-read.table("clipboard", h=T)
> dados
trat rep A
1 C 1 6.00
2 C 2 6.00
3 C 3 6.00
4 C 4 6.00
5 E 1 2.70
6 E 2 1.52
7 E 3 2.50
8 E 4 4.80
> qqnorm(dados$A)
> qqline(dados$A, lty=2)
> wilcox.test(dados$A~dados$trat)
Wilcoxon rank sum test with continuity correction
data: dados$A by dados$trat
W = 16, p-value = 0.02107
alternative hypothesis: true location shift is not equal to 0
Warning message:
In wilcox.test.default(x = c(6, 6, 6, 6), y = c(2.7, 1.52, 2.5, :
cannot compute exact p-value with ties
> boxplot (dados$A~dados$trat, las=1)

robertamfs- Mensagens : 32
Data de inscrição : 17/09/2018
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por Prof. Marcos Seg Nov 12, 2018 10:13 am
Olá, Roberta!
Se os dados tem medidas repetidas no tempo, as coisas podem ficar ligeiramente mais complicadas... Em uma situação normal, o ideal seria uma anova de medidas repetidas, e ela não tem um equivalente não paramétrico para ser usado. Existe uma saída às vezes usada com o teste de Friedman, mas é como que uma adaptação para a situação.
Eu diria, então, que num primeiro momento pode ser interessante tentar usar a anova de medidas repetidas mesmo, e conferir se os resíduos satisfazem os pressupostos da análise. Em caso positivo, eu seguiria normalmente com a análise, apenas relatando a modificação feita com os dados acima de cinco.
Caso os resíduos não atendem os pressupostos, talvez uma transformação ajude. Mas se não resolver, eu acho que a melhor saída é seguir para algo mais complexo, como trabalhar com modelos mistos (está em um dos bônus, recomendo assistir depois do de GLMs).
Abraços
Se os dados tem medidas repetidas no tempo, as coisas podem ficar ligeiramente mais complicadas... Em uma situação normal, o ideal seria uma anova de medidas repetidas, e ela não tem um equivalente não paramétrico para ser usado. Existe uma saída às vezes usada com o teste de Friedman, mas é como que uma adaptação para a situação.
Eu diria, então, que num primeiro momento pode ser interessante tentar usar a anova de medidas repetidas mesmo, e conferir se os resíduos satisfazem os pressupostos da análise. Em caso positivo, eu seguiria normalmente com a análise, apenas relatando a modificação feita com os dados acima de cinco.
Caso os resíduos não atendem os pressupostos, talvez uma transformação ajude. Mas se não resolver, eu acho que a melhor saída é seguir para algo mais complexo, como trabalhar com modelos mistos (está em um dos bônus, recomendo assistir depois do de GLMs).
Abraços
Prof. Marcos- Mensagens : 678
Data de inscrição : 23/12/2015
Idade : 42
Localização : Maceió, AL -
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por robertamfs Seg Nov 12, 2018 1:47 pm
Boa tarde,
Grata pelo retorno.
Apliquei essa fórmula de ANOVA de medidas repetidas no tempo para que possa ser gerado o modelo
#criando modelo de ANOVA
resultado.anova<-aov(dados$temperature~dados$tratamento*dados$dia+Error
(dados$relica/dados$tratatamento))
Só que quando vou verificar os pressupostos de normalidade colocando $residuals dá erro:
qqnorm(resultado.anova$residuals)
Error in qqnorm.default(resultado.anova$residuals) :
y is empty or has only NAs
shapiro.test(resultado.anova$residuals)
Error in shapiro.test(resultado.anova$residuals) :
is.numeric(x) is not TRUE
Tem alguma outra fórmula para ANOVA de medidas repetidas no tempo ou, nesse caso, a fórmula para verificação de normalidade é outra?
Na aula bônus de GLM - Prof. Frederico Neves não é exemplificado nem dado pistas de como fazer medidas repetidas no tempo. E no bônus de Modelos Mistos traz um exemplo, mas não fala se precisa de um número amostral de réplicas mínimo. Tem esse pressuposto? Tem alguma literatura que aprofunde mais a interpretação dos resultados?
Att. Roberta
Grata pelo retorno.
Apliquei essa fórmula de ANOVA de medidas repetidas no tempo para que possa ser gerado o modelo
#criando modelo de ANOVA
resultado.anova<-aov(dados$temperature~dados$tratamento*dados$dia+Error
(dados$relica/dados$tratatamento))
Só que quando vou verificar os pressupostos de normalidade colocando $residuals dá erro:
qqnorm(resultado.anova$residuals)
Error in qqnorm.default(resultado.anova$residuals) :
y is empty or has only NAs
shapiro.test(resultado.anova$residuals)
Error in shapiro.test(resultado.anova$residuals) :
is.numeric(x) is not TRUE
Tem alguma outra fórmula para ANOVA de medidas repetidas no tempo ou, nesse caso, a fórmula para verificação de normalidade é outra?
Na aula bônus de GLM - Prof. Frederico Neves não é exemplificado nem dado pistas de como fazer medidas repetidas no tempo. E no bônus de Modelos Mistos traz um exemplo, mas não fala se precisa de um número amostral de réplicas mínimo. Tem esse pressuposto? Tem alguma literatura que aprofunde mais a interpretação dos resultados?
Att. Roberta
robertamfs- Mensagens : 32
Data de inscrição : 17/09/2018
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por Prof. Marcos Qui Nov 22, 2018 11:31 am
Oi, Roberta!
Possivelmente existe alguma coisa estranha nos dados em si, que acabou gerando a mensagem de erro. Olhando o comando da anova, por exemplo, notei que está escrito "dados$relica". Está certo, ou seria replica? Isto poderia explicar o erro.
Caso não seja isso, confira o summary das variáveis, e veja se tem algo estranho. Qualquer coisa poste o resultado do summary aqui pois pode facilitar para ajudar.
Abraços
Possivelmente existe alguma coisa estranha nos dados em si, que acabou gerando a mensagem de erro. Olhando o comando da anova, por exemplo, notei que está escrito "dados$relica". Está certo, ou seria replica? Isto poderia explicar o erro.
Caso não seja isso, confira o summary das variáveis, e veja se tem algo estranho. Qualquer coisa poste o resultado do summary aqui pois pode facilitar para ajudar.
Abraços
Prof. Marcos- Mensagens : 678
Data de inscrição : 23/12/2015
Idade : 42
Localização : Maceió, AL -
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por robertamfs Qui Nov 22, 2018 5:41 pm
Boa tarde.
O script foi corrigido e não foi esse o problema de erro. O que dá a impressão é que como são dados de medidas repetidas aparecem dois resultados de residuals e nos dados do resultado lista apenas 3 resultados: (Intercept) ; dados$replica ; Within. Não aparece residuals.
Segue summary do resultado:
> summary(resultado.anova)
Error: dados$replica
Df Sum Sq Mean Sq F value Pr(>F)
dados$trat 1 0.451 0.4513 0.507 0.503
Residuals 6 5.340 0.8900
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
dados$semana 8 61.12 7.640 113.258 <2e-16 ***
dados$trat:dados$semana 8 0.82 0.103 1.524 0.174
Residuals 48 3.24 0.067
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> qqnorm(resultado.anova$residuals)
Error in qqnorm.default(resultado.anova$residuals) :
y is empty or has only NAs
> qqline(resultado.anova, lty=2)
Error in xi == xj : comparison of these types is not implemented
O script foi corrigido e não foi esse o problema de erro. O que dá a impressão é que como são dados de medidas repetidas aparecem dois resultados de residuals e nos dados do resultado lista apenas 3 resultados: (Intercept) ; dados$replica ; Within. Não aparece residuals.
Segue summary do resultado:
> summary(resultado.anova)
Error: dados$replica
Df Sum Sq Mean Sq F value Pr(>F)
dados$trat 1 0.451 0.4513 0.507 0.503
Residuals 6 5.340 0.8900
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
dados$semana 8 61.12 7.640 113.258 <2e-16 ***
dados$trat:dados$semana 8 0.82 0.103 1.524 0.174
Residuals 48 3.24 0.067
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
> qqnorm(resultado.anova$residuals)
Error in qqnorm.default(resultado.anova$residuals) :
y is empty or has only NAs
> qqline(resultado.anova, lty=2)
Error in xi == xj : comparison of these types is not implemented
robertamfs- Mensagens : 32
Data de inscrição : 17/09/2018
Re: como fazer teste de hipótese para comparar valores exatos com valores >5
por Conteúdo patrocinado
Conteúdo patrocinado
» Uso de Ctrl+R para executar uma função digitada no script (como fazer no Mac???)
» Como fazer um gráfico com dois eixos Y
» Atividade do módulo 1
» COMO FAZER O R IDENTIFICAR MEUS GRUPOS NO CLUSTER?
» Teste para homogeneidade das variâncias em 4.12- O teste T
» Como fazer um gráfico com dois eixos Y
» Atividade do módulo 1
» COMO FAZER O R IDENTIFICAR MEUS GRUPOS NO CLUSTER?
» Teste para homogeneidade das variâncias em 4.12- O teste T
Página 1 de 1
Permissões neste sub-fórum
Não podes responder a tópicos|
|
|